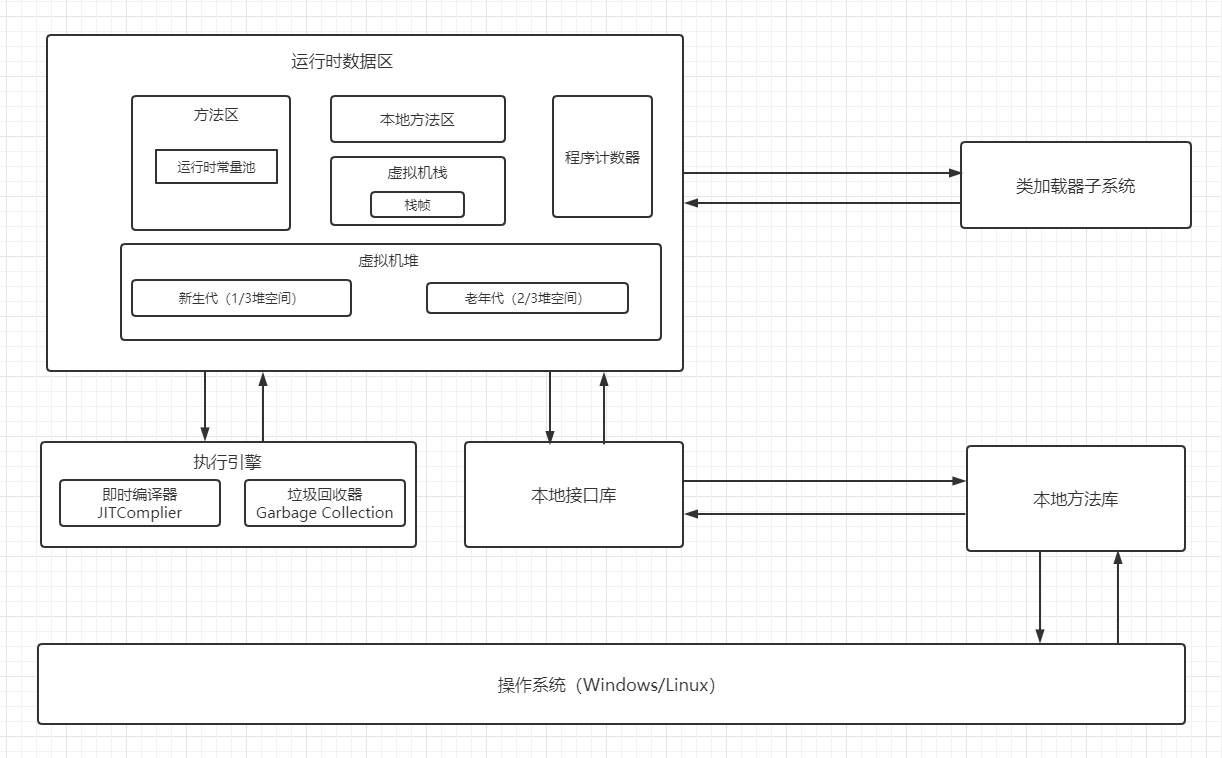
FullGC多的原因,如何优化
原因:FullGC触发的原因是老年代满了,需要整堆回收
对象被放到老年代有原因:
- 大对象直接分配到老年代
- 对象经历了很多次GC,年龄超过15
- 在Survivor区中,超过某个年龄的对象占比超过50%,超过年龄的对象都转移到老年代
- 空间分配担保,导致老年代满了,或者需要担保的空间太大无法满足要求
优化:
- 增大JVM参数中堆内存的设置,看是否需要修改老年代和新生代的比例
- 减少不必要的对象创建,对象用完赋null值帮助回收
- 尽量不定义大对象
- 如果现在使用的是CMS,评估是否可以使用G1收集器
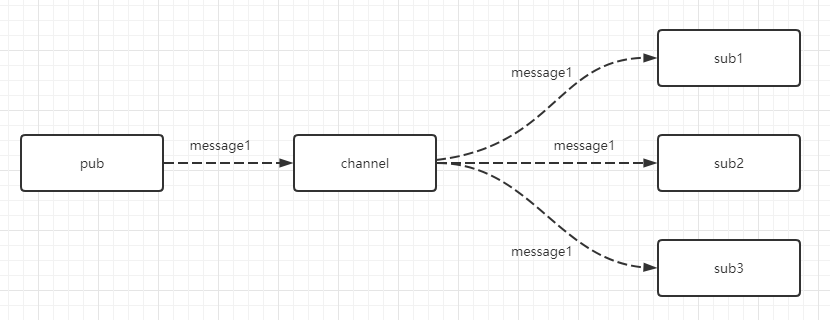
MQ怎么保证消息不丢失?
MQ保证消息不丢失从两个方面来看:客户端的使用和服务端的配置
客户端使用
- 发送消息时,使用同步发送或者异步发送+check的机制,保证客户端发送消息时成功被服务端接收了
- 处理消息时,先进行消息的业务处理,等业务逻辑处理完之后,再返回消息的消费ack,如果ack异常了,可以考虑对消息进行持久化处理
服务端配置
- 在接收到消息后,采用同步刷盘的机制来保存消息到磁盘
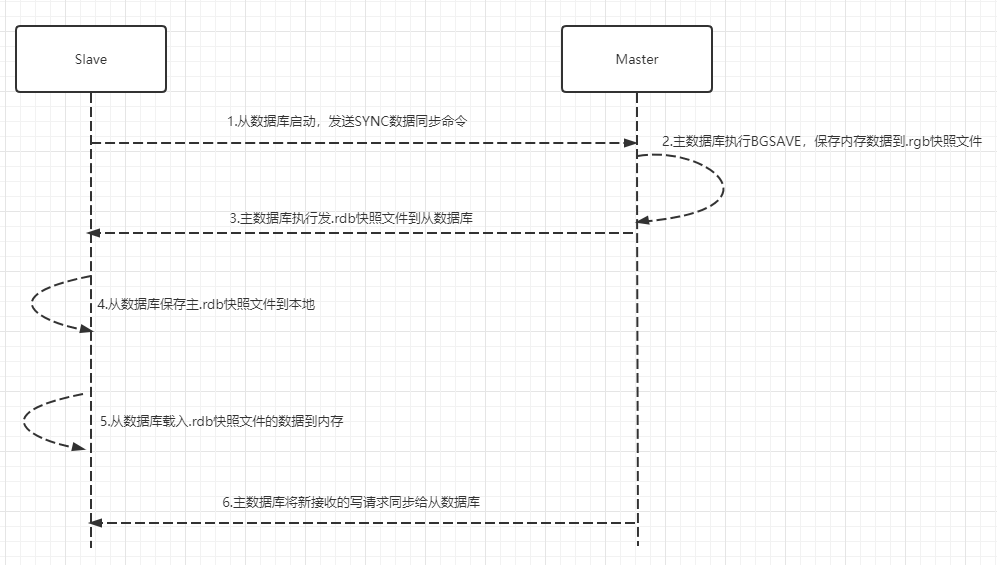
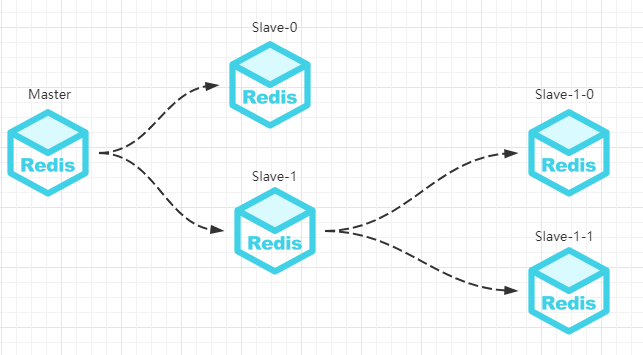
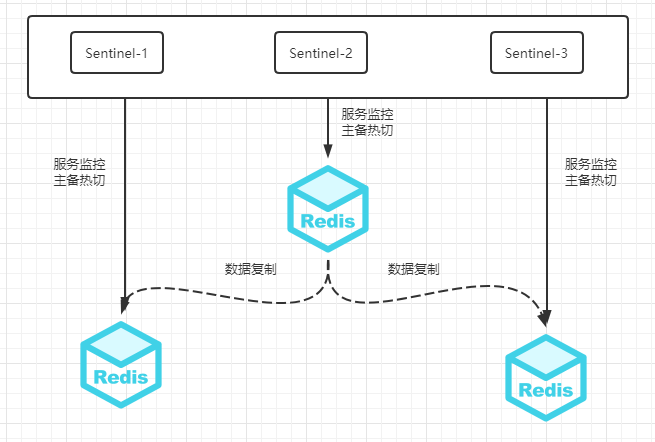
- 主从同步,保证即使遭遇系统宕机、磁盘损坏的情况下也保证消息的不丢失
MQ如何处理重复消费
- 看业务是否具有天然的幂等性,例如在订单类系统中,可以通过使用状态判断来看消息是否已经被处理过了
- 如果不具备幂等性,可以考虑使用setnx来做,当收到消息之后,获取消息的唯一标示,通过唯一标示来做一个分布式锁,消费结束时如果消费成功,执行ack,这个锁就放着不动;消费失败,释放锁,不执行ack
ID生成器的原理
ID生成器是为了全局生成唯一ID的
比较常见的有UUID、数据库自增主键、雪花算法
雪花算法的结构:时间戳 + 机器ID + 序列号
缓存雪崩、缓存击穿、缓存穿透
缓存雪崩
大量缓存在同一时间失效,导致大量请求打到MySQL,或者Redis服务不可用了,导致请求直接访问到MySQL
解决方案:
- 失效时间的设置尽量在原定时间上加上一个随机数,避免大量key同时失效
- 搭建Redis集群,提高可用性
缓存击穿
缓存击穿主要是因为某个热点key在Redis突然消失了,请求全都打到了MySQL
解决方案:
- 热点key不设置失效时间
- 避免误删操作(代码、人工)
- 布隆过滤器
缓存穿透
连续请求某一个不存在key,导致请求直接打到数据库
解决方案:
- 如果发现持续访问一个不存在的key,可以在Redis中放一个默认值,或者执行降级
- 在前端或者web层就校验key的合法性,避免不合法的key放进来
MySQL分库分表
分库分表的策略采用主键id和表个数取模的策略
如果数据量持续增加,可以考虑增加分表的张数,分表数量 * 2,减少数据迁移工作
或者最开始就使用一致性Hash
还可以考虑范围分片的方法,并对历史数据执行归档
CPU 100% 的问题
简要步骤:
- 找到最耗CPU的进程
- 找到最耗CPU的线程
- 查看堆栈,定位线程在干什么,定位代码
步骤一、找到进程
- 执行top -c,显示进程运行信息列表
- 键入P(大写),进程按照CPU使用率排序
- 找出最耗CPU的进程id,例如10778
步骤二、找到线程
- 执行top -Hp 10778,显示一个进程的线程运行信息列表
- 键入P(大写),线程按照CPU使用率排序
- 找出最耗CPU的线程id,例如10084
步骤三、看看线程在干什么
- 首先将线程PID转化为16进制,使用printf “%x\n” 10084,得到对应16进制为: 2764
- 通过jstack查看堆栈信息,jstack 10778 | grep ‘0x2764’ -C5 —color,得到线程堆栈
- 找到线程对应的线程名称,找到对应代码
线程池的参数评估
首先要明确任务的类型
如果是CPU密集型任务,那么核心线程数设置为:CPU核数+1
如果是IO密集性任务,那么就需要大致估算出IO时间和CPU时间的比例,最佳线程数就是
[(IO耗时/CPU耗时)+1]*CPU核数
上面说的是核心线程数,那么最大线程数则可以比核心线程数稍微多一些
然后就是阻塞队列了,阻塞队列不宜使用LinkedBlockingQueue(其实LinkedBlockingQueue也是有界的,为Integer的最大值,并且也可以设置容量),而应该使用有界的ArrayBlockingQueue,这个队列大小也需要根据访问量来估计,减去核心线程数在处理的任务,得出一个数值